検定と推定
検定と推定に関してはこっちの記事のほうにもっと書きました。
数理統計:点推定、区間推定、検定についてのメモ - 雑なメモ
標本分布について
- 母集団(population)と標本(sample)
- 母集団とは、統計をとって特徴を調べたいものの対象の全体。日本のカブトムシの大きさを調べるとして、実際に虫かごに入れたカブトムシが標本、日本にいるカブトムシが母集団。
- 統計量(statistic)と推定量(estimator)
- 標本に対応する確率変数の関数の値を統計量、母数(調べたい母集団の分布を決定する値)を推定するための統計量を推定量という。
- どの推定量が最も母数に近くなるか?
- この判断基準が必要であるとわかるけれど、あとまわし。
- 以下大きな標本とは標本数30以上のものをさす、つまりt分布がほぼ正規分布に重なる状態、標本平均が中心極限定理によって正規性をもつ状態のことをさしている。
標本平均  の分布
の分布
母集団は平均 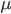 ,分散
,分散  であるとしてここから標本をいくつかとったとき、標本平均 は平均 に近い確率はどれくらいか知りたいのでその分布を求める。ある確率変数Aの期待値をE(A)と書くことにする。
であるとしてここから標本をいくつかとったとき、標本平均 は平均 に近い確率はどれくらいか知りたいのでその分布を求める。ある確率変数Aの期待値をE(A)と書くことにする。

となるから標本平均の平均値も母集団の平均に等しい。しかし分散は単純ではないらしい。標本は無作為、つまり各標本は独立して採取されるとして。

となる、つまり標本数nが大きければ大きいほど標本平均のばらつきが少なくなるのだから標本が大きいほど母集団の平均と標本平均は近い可能性が高い。
比率の推定量
比率とは全体のうちどれだけの割合が○×か?ということ。
なので標本は「○×の性質を持っているか?」という問いに対応して「yes or no」しかない。これに「1 or 0」を対応させれば、100個中30個で1なら比率は 30/100 で三割、みたいになる。
推定したい比率を とかいて、yesと答えた人の数を
とかいて、yesと答えた人の数を と書く。標本での比率と母集団での比率を比べるために標本の比率の平均値を求めたいけど、これは先に述べた標本平均の分布で確率変数が1か0の値しかとれない場合と考えれば標本の比率の平均値は
と書く。標本での比率と母集団での比率を比べるために標本の比率の平均値を求めたいけど、これは先に述べた標本平均の分布で確率変数が1か0の値しかとれない場合と考えれば標本の比率の平均値は

つまり、母集団の比率に等しくなる。
標本の比率の分散も同じように求まるけれど、よく使うから定式化。
となるから、比率の標本分布はN( )になる。
)になる。
検定と推定に使う分布
一番よく使う分散、平均の信頼区間の推定をするためには分散( の足し算)<-> 二乗の変数の和の分布 といった新しい分布を利用する必要がある。だけど、統計学者じゃないかぎり、そのときに使う分布と性質を知っておけばおk.
の足し算)<-> 二乗の変数の和の分布 といった新しい分布を利用する必要がある。だけど、統計学者じゃないかぎり、そのときに使う分布と性質を知っておけばおk.
- χ二乗分布
- 標準正規分布をもつ独立な確率変数の二乗和の分布

とするとき、Yは自由度nのχ二乗分布。
- F分布
- 確率変数X、Yが独立でそれぞれが
 の自由度のχ二乗分布に従うとして
の自由度のχ二乗分布に従うとして
- 確率変数X、Yが独立でそれぞれが
 は自由度()のF分布。
は自由度()のF分布。
- t分布
- 自由度(1,n)のF分布の変数Zに対して
 となるwの分布はt分布。
となるwの分布はt分布。
- 自由度(1,n)のF分布の変数Zに対して
分布の式は少し複雑(だけど、積分とかから導出できる)なので略。そして一般教養の試験には出ないらしかった。
- 標本分散の推定量
標本分散の分布を求めるときに二乗の和が出てくる部分がχ二乗分布に関わってくる。

は自由度nのχ二乗分布を持つことがわかるから、これを標本から母集団の性質を推定するのに使うには標本分散や標本平均を使ってこの式について考える。

は自由度nのχ二乗分布に従っていて、その不偏推定量

は自由度n - 1のχ二乗分布に従う。
点推定と信頼区間の推定
ここでは、母集団は正規分布に従っている、などとわかっていてその平均や分散を推定する。つまり、母集団の分布の関数のパラメータはわかってないけど関数の形式はわかってる場合を考えてこれをパラメトリックな時という。
- 点推定と区間推定
- 点推定 平均値は μ だと推定
- 区間推定 平均値は [a,b] 区間にある確率が90%
みたいな。ざっくりし過ぎかも。点推定は連続変数なら一致する確率は厳密には0。
- 推定量のもつべき性質
- 母数を推定するための関数はどういうものが”良い”といえるのか考える。
- 普遍性
- 推定量の平均値が母数に一致していること
- たとえば、不偏分散など。
- 普遍性
- 母数を推定するための関数はどういうものが”良い”といえるのか考える。
となるから、平均が母数に一致する<->不偏推定量。そして、標本分散/(n-1) は自由度n-1のχ二乗分布に従うのを先ほどやった。ここで二乗の平均は分散の二乗+平均の二乗という式を使っている。
- 最尤推定法
尤度関数を母数に関して微分して0になるように母数を定める方法。授業では取り扱ってないので時間があれば別に記述したい。
区間推定
- 正規母集団の母平均の区間推定
標本がたくさんあるときとないときでは計算に違いが出てくるが基本的な部分は同じ。

のだから、1 - a という数値を一回さだめると、
と式変形できる。
- 正規母集団の母分散の区間推定
χ二乗分布を用いることがなんとなくわかる。

ことを思い出す。標本分散を用いて は自由度nのχ二乗分布に従う、そして不偏分散を用いると、不偏分散
は自由度nのχ二乗分布に従う、そして不偏分散を用いると、不偏分散 は自由度n-1のχ二乗分布に従う。だから
は自由度n-1のχ二乗分布に従う。だから
と区間が求められる。
- 標本数が少ないときの区間推定
標本が少ないと、標本の数が少なすぎてデータにばらつきがどれくらいあるのかを判断できない。そのため、正規母集団と仮定して母平均、母分散を推定するのではなくt分布を用いる。データのばらつきを母集団に近づけることができないハンデ分だけ保守的な結果(より範囲の広い結果)になる。

はN(0,1)に従ったけれど、この分母のσが標本が少なすぎてはっきりしないので

を考える、このTは自由度n-1のt分布に従う。
と求まる。
仮説検定
- 第一種の過誤と第二種の過誤
- 第一種:ほんとは正しい仮説を間違って棄却
- 第二種:ほんとはちがう仮説を間違って採択
かなりざっくりと。そしてこの第一種の過誤をしてしまう確率をαとする。このαを有意水準と言う。
- 仮説検定のステップ
- 1.帰無仮説と対立仮説(証明したい仮説)を立てて、
- 2.有意水準αを定めたら、
- 3.棄却領域(帰無仮説を棄却する領域)を求めて、
- 4.棄却or採択
かなり端折っているけれど、この第三ステップがメイン。
検定統計量(検定の対象となる統計量)を定めて、片側検定か両側検定かを定めて、それに応じて臨界値(棄却or採択の境目となる値)を計算する必要がある。
標本がたくさんあるときの母平均に対する仮説検定
H_n : 帰無仮説・null hypothesis
H_a : 対立仮説・alternative hypothesis
と書くことにする。母集団の平均はμと書く。

といった仮説が立てられる。
- 母集団の分散が既知の場合
標本平均の分布の平均と母集団の分布の平均は一致することを思い出して、また母集団の分散をσとすれば標本の分散は

とかける。そして既知の分布に従うような統計量でないと検定できないので標準正規分布に従う検定統計量Zを

と決めればいいことに気づく。有意水準をαとすれば、有意水準を超えるような値をとる可能性は1 - αであるということなので、Zが標準正規分布ならば正規分布の両端( )を超える値を出す確率が1-αということ。片側検定ならば2で割る必要はない。
)を超える値を出す確率が1-αということ。片側検定ならば2で割る必要はない。
- 母集団の分散が未知の場合
標本から標本分散を求めると

となるが、不偏推定量をもちいると

となる、このため検定統計量をきめるときに

は形が先ほどと似ているがこれは正規分布に従うのではなく自由度n-1のt分布に従う。(先ほどとちがって、分母にも標本由来の数値が現れていることから先ほどと違う分布を使うべきだと気づく、かも)
比率の仮説検定

と仮説を立てる。p_1の不偏推定量は標本平均と同じで と記述する。このときこの標本平均に一致するの分散は標本平均の分散
と記述する。このときこの標本平均に一致するの分散は標本平均の分散 と書ける。
と書ける。
二つの母集団間の平均に差があるかを調べる仮説検定
絶対式を忘れてしまうのがこれな気がする。繰り返しやれば覚えるかもしれないが、なので導出までしてみる。参考文献は数理統計学ハンドブックです。
と書くことにする。X、Yは独立しているとすれば の不偏推定量であることが独立しているならば平均の加法性があることからわかる。
の不偏推定量であることが独立しているならば平均の加法性があることからわかる。
いま、Xの標本数を n_x , Yの標本数を n_y として、 n_x + n_y = n であるとする。

と書くことにすれば、このλは標本全体のうちX、Yの占める割合を表している。中心極限定理によって

ことを思い出せば
ことがわかる。Yについても

ことがわかる。ここで差の信頼区間を求めるためにはふたつの母集団の標本から得た式(上の)を結びつける必要があるけれど、XとYが独立であると断っているのでそれができて、

と求められる。正規分布表で信頼区間を求めるために分散が1になるようにすれば

は標準正規分布N(0,1)に従うとわかる。よって有意水準をαとすれば
とすることができる。 こうして、母平均の差の検定をするための検定統計量がわかった...!
- 母集団の分散が既知の場合は

- 母集団の分散が未知の場合は

を用いる。前者は正規分布表、後者はt分布表を用いる必要がある。後者の自由度の式は複雑だけど二つの母集団の分散が未知だけど等しいと仮定している場合は自由度n - 2と定まる。

