情報源及び出典、参照元
- Stanford engineering everywhere artificial intelligence | machine learning
- Stanford School of Engineering - Stanford Engineering Everywhere
- 講師:Andrew Ng (敬称略) 、著作権表示及び授業関連資料は上記サイトを参照してください。
- この記事の中の図の引用元
- Stanford School of Engineering - Stanford Engineering Everywhere
- それぞれの引用した図で、引用元(上記ページのpdfファイル名)を明記します。
- Stanford engineering ever に関するFAQ
- http://see.stanford.edu/see/faq.aspxを参照して下さい。
- 元サイトの著作権表示 Attribution 3.0 United States (CC BY 3.0 US) の日本語訳はここにありますが、誤解が無いように必ず英語ページを見てください。そして、この記事も同様にCC BY 3.0 USに従います。
※上記のページおよびpdf、上記以外の参考文献や関連ページを注釈の形でページ末尾に改めて記載します。
関連する文献
 |
 |
 |
黄色いのがいいです。
第一回授業メモ
Lecture 1 | Machine Learning (Stanford) - YouTube
主な内容はこのコースでどのようなことを学ぶか、それを使った実際例の紹介でアルゴリズムや理論については第二回から。
Supervised learning(教師あり学習)*1


Learning theory/学習理論
Algorithmic learning theory is a mathematical framework for analyzing machine learning problems and algorithms.*4
今は省略、学習をするのにどれほどのデータ数が必要なのか?などの決定に必要。
The Cocktail Party Problem
第一回の補足資料からのメモ
なし。
(第一回おわり)
第二回授業メモ
内容は
- 線形回帰
- 最急勾配法(gradient descent)*5
- 正規方程式(最小二乗法)
線形回帰

(引用:cs229-notes1_pdf(3_30ページ))
新しい表記の導入

学習アルゴリズムのモデル化

としたら、適切な写像

を見つけるのが機械学習の目的。そして慣例に従ってこの関数をhypothesisと呼ぶ。つまり機械学習を簡単にモデル化すると

cs229-notes1.pdfのpage2より図を引用
と書くことができる。この例では入力データは二次元だから写像hは

と書くことにする。さらに簡単にするためにダミーの値 を導入すれば、この式を簡略化して
を導入すれば、この式を簡略化して

と書ける。この授業ではベクトルに矢印をつけない(しこの記事でもつけない)から文脈に従って適切に判断する。この授業ではしばしば は特徴数、つまり入力データの次元数。
は特徴数、つまり入力データの次元数。
 は写像
は写像 をコントロールする変数であり、パラメータと呼ぶ。
をコントロールする変数であり、パラメータと呼ぶ。
どのように学習するのか
学習するために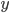 に近いことを表す指標がほしい。ここでは指標の一つとしてcost function:
に近いことを表す指標がほしい。ここでは指標の一つとしてcost function:

を定義する。この値が0に近いほど良い学習アルゴリズムである。つまり学習アルゴリズムは となるパラメータを探す。それを探す一つの方法が最急勾配法(gradient descent)である。
となるパラメータを探す。それを探す一つの方法が最急勾配法(gradient descent)である。
最急勾配法(gradient descent)
定式化すると、

を繰り返すことでパラメータの値を更新する。
 は最も増加する方向へのベクトルなのだから、
は最も増加する方向へのベクトルなのだから、 は最も減少する方向へのベクトルでこのアルゴリズムを繰り返せば目的関数を最小化できる。しかし最急勾配法は「初期値によって収束する場所が違う」場合が存在するし、だから必ずしも最適解がもとまる訳ではない。つまり求まるのは大域最適解ではなく局所最適解が求まる。
は最も減少する方向へのベクトルでこのアルゴリズムを繰り返せば目的関数を最小化できる。しかし最急勾配法は「初期値によって収束する場所が違う」場合が存在するし、だから必ずしも最適解がもとまる訳ではない。つまり求まるのは大域最適解ではなく局所最適解が求まる。
ここで板書にて”訓練集合がただ一つの要素しかもたない”場合の例を示す。(32:00頃)

引用元:cs229-notes1_pdf(4_30ページ)

であり、どれくらいのステップで学習するかを定めるパラメータ。この例から授業のはじめに例に挙げた訓練集合の学習アルゴリズムのためのcost functionに対する最急勾配法の式は

と書くことができる。
Stocastic gradient discent(確率的勾配降下法)*6

引用:cs229-notes1_pdf(7_30ページ)
最急勾配では一ステップのたびにすべてのデータについてコスト関数をけいさんするから一ステップで かかるが、Stocastic gradient discent(確率的勾配降下法)では毎回一つのデータに対してしかコスト関数を計算しない。
かかるが、Stocastic gradient discent(確率的勾配降下法)では毎回一つのデータに対してしかコスト関数を計算しない。
勾配ベクトルの導入*7
省略。コスト関数 の勾配ベクトルを導入。
の勾配ベクトルを導入。
次に行列の微分を定義する。詳細はMITの資料*8を参考にした。以上の知識を知っていれば講義の50分以降はかなり飛ばしてみれる。今までに導入した最急勾配法やコスト関数を行列で表現して簡潔に表す。その結果

引用:cs229-notes1_pdf(11_30ページ)
と書き表すことができる。行列 の
の 行は
行は  、つまり訓練集合の入力値である。
、つまり訓練集合の入力値である。は目標値のm次元ベクトルである。ここからある訓練集合がが与えられたときの最小二乗のコスト関数を最小にするパラメータは

と求めることができる。
第二回の補足資料*9からのメモ
- ordinary least squares(最小二乗法)*10
コスト関数の式の一般名称。これはさらに広いアルゴリズムのクラスの特別な場合であり後ほど分かる。最急勾配法では訓練集合がたった一つのときを例にとってパラメータベクトルのj要素の更新は

と書くことができる。これはWidrow-Hoff learning rule*11として一般的に知られている。
Widrow-Hoff learning rule
この規則には以下の性質があり、それらは直感的にも合致する。
- 目標値
に近い
 はパラメータの変更をほとんどしない
はパラメータの変更をほとんどしない - 目標値はパラメータを大きく変更する
ただし最急勾配法は一般に局所最適解に収束するがそれが大域最適解とは保証されていない、大域最適解がただ一つ存在するならば最急勾配法は常に同じ値に収束すると言える。以下は二次関数に対して最急勾配を適用したときの軌道。
stochastic gradient descent(確率勾配)
batch gradient descentが全体のデータを一回パラメータを更新するたびにとりこんで計算するたびに対して、stochastic gradient descent(確率勾配)はデータをひとつ取り込んでそれに対してパラメータを補正をすべてのデータに大して繰り返す。この手法は概して全体のデータを一回パラメータを更新するたびにとりこんで計算するのと十分”近い”解をだす。一ステップの計算時間は となる.
となる.
正規方程式を記述するための行列の導入

引用:cs229-notes1_pdf(9_30ページ)
 とする。
とする。 ならば
ならば だから
だから に対してはトレースが使用できる。トレースしたら
に対してはトレースが使用できる。トレースしたら と一次元の値になるのだから
と一次元の値になるのだから と定義することができる。そして
と定義することができる。そして![{ [ \nabla_A f(A) ]_{ij} = {B^T}_{ij} }](https://cdn-ak.f.st-hatena.com/images/fotolife/m/misos/20201118/20201118145923.png) と一つ目の等式から言える。
と一つ目の等式から言える。 さらに計画行列(design matrix)*12を定義する。計画行列 はn個の特徴をもついとつの入力値を行に対応させたもの。
はn個の特徴をもついとつの入力値を行に対応させたもの。 と定義したベクトル
と定義したベクトルを用いれば、

引用:cs229-notes1_pdf(10_30ページ)
と書くことができる。さらに最少二乗法の式は

と簡単に記述できる。以上の記述と公式を用いると
引用:cs229-notes1_pdf(11_30ページ)
と式を変形できる。コスト関数の勾配が0になる箇所が極値をとるのだから=0として
なのだから

(第二回おわり)
- 単語
- intercept term:切片項
- ordinary least squares:最小二乗法
第三回授業メモ
回帰問題において最小二乗和をコスト関数に用いる確率的な解釈
この項では目標値と入力値の関係を

とモデル化する。 は目標値と入力値の誤差を表す項(error term,モデル化されないような値やランダムノイズ)と見れる。そしては平均
は目標値と入力値の誤差を表す項(error term,モデル化されないような値やランダムノイズ)と見れる。そしては平均 ,分散
,分散 の独立で同一の分布に従うと仮定する。すると誤差を含む確率は
の独立で同一の分布に従うと仮定する。すると誤差を含む確率は

と書くことができる。この事実と であることから
であることから

と導ける。コロンを使うのは が確率変数では無いことに気をつけるため。
が確率変数では無いことに気をつけるため。
尤度関数*13の導入
上記の式を用いて、ある計画行列と目標値のベクトルが与えられたとき(つまりある訓練集合が与えられたとき)、尤度関数は


引用:cs229-notes1_pdf(13_30ページ)
と書く。するとこの式を最大化するには の項を最小化する必要があることが分かる。この式はまさに最小二乗和の式!
の項を最小化する必要があることが分かる。この式はまさに最小二乗和の式!
分類問題*14(classificatin problem)(映像50:00頃から)
つまり、ここからは目的値が離散値をとる。資料はこれ*15。簡単のためにbinary classification problem*16,つまり となるものを考える。以下では目標値に付いて、
となるものを考える。以下では目標値に付いて、
 : negative class
: negative class : positive class
: positive class
と呼ぶことにする。
ロジスティック回帰*17
目標値が離散で特にいまは1か0の場合を考えている、この時(講義中での説明にあるように)すごく簡単に「今までの線形回帰を適用してもあまり正確に事象を捉えられていない」例を作ることができる。それにこれまででは の定義域は明確ではなかった(からすごく大きな値や小さな値をとれる場合もあった)けれど今は目標値が0か1でしか無いのだからこの写像hを替えたほうがいいと考える。そこでシグモイド関数*18を導入して
の定義域は明確ではなかった(からすごく大きな値や小さな値をとれる場合もあった)けれど今は目標値が0か1でしか無いのだからこの写像hを替えたほうがいいと考える。そこでシグモイド関数*18を導入して

と定義する。このシグモイド関数 には
には
 が漸近線
が漸近線
引用:cs229-notes1_pdf(17_30ページ)

と考える。これらの仮定を一まとめにひとつの式

と記述することができる。さらに今データは独立して得られると考えると計画行列と目標値ベクトル[tex{ \vec{y} }]が与えられたら尤度関数は

と記述できて、この対数をとると

とできる。この式の最大化をするためにΘに関して微分をすると

引用:cs229-notes1_pdf(18_30ページ)

とパラメータを更新していけばいいと分かる。これは線形回帰のパラメータの確率勾配を用いた更新とまったく同じ形の式(だけどアルゴリズムとしては違う、なぜなら関数 の定義を変えているから)。これが同じになる理由は一般線形モデル*22に関する説明で後ほど分かることになる。
の定義を変えているから)。これが同じになる理由は一般線形モデル*22に関する説明で後ほど分かることになる。
(第三回おわり)
第四回授業メモ
最急勾配とニュートン法について
- 講義の16:30までの内容
- ニュートン法の紹介
- 収束の速さが最急勾配と違うことの紹介
- ヘッセ行列の紹介
最適化:非線形計画について(最急降下、ニュートン、KKT条件)とNP困難問題に対する動的計画法 - 雑なメモ
最適化:非線形計画+組み合わせ最適化のまとめのメモ - 雑なメモ
このあたりに書いた気がするので省略します。
一般線形モデル( generalized linear models )*23
- 復習(recap)
- 目標値が連続値→最少二乗のコスト関数
- 目標値が離散値0,1→ロジスティック回帰
- 目標値
... what I want to do now is show that both of these are special cases of the cause of distribution that’s called the exponential family distribution. And in particular, we’ll say that the
costclass of distributions, like the[inaudible]Bernoulli distributions that you get as you vary theta, we’ll say thecostclass of distributions is in the exponential family if it can be written in the following form. P of Y parameterized by theta is equal to B of Y[inaudible](映像の板書みればわかる、22:00頃), okay.
こちらより一部改編して引用*24
つまり今までにでてきたベルヌイ分布やガウス分布はすべて指数型分布族のなかの一部であって今からそれについて紹介するということ。
Exponential family(指数型分布族)*25
なんと日本語のWikiが存在しなかった。なので関連するページをメモ。そのあと自分なりに書くも多分間違いある。
指数型分布族に含まれる分布は一般的に以下のような式で記述することができる。

この式の中のパラメータを指定した特別な場合がこれまでに出てきたガウス分布やベルヌーイ分布。そしてそれらのパラメータを
 (自然パラメータ)
(自然パラメータ) (十分統計量*26 )
(十分統計量*26 )
と記述する。 は正規化定数(normalization constant)、つまり確率の和を1にするために利用していると考えればいい。いったんこの式の中の十分統計量を定めれば、
は正規化定数(normalization constant)、つまり確率の和を1にするために利用していると考えればいい。いったんこの式の中の十分統計量を定めれば、 によって
によって でパラメータ化された確率分布族を定義できて、をいじれば違う分布が出来上がるらしい。そこでベルヌーイ分布とガウス分布が実際にこの式で記述できることを見る。
でパラメータ化された確率分布族を定義できて、をいじれば違う分布が出来上がるらしい。そこでベルヌーイ分布とガウス分布が実際にこの式で記述できることを見る。
- ベルヌーイ分布*27の場合
平均 のベルヌーイ分布を考える。
のベルヌーイ分布を考える。 と定義域を定める。するとすっっと前の記述をもってくると
と定義域を定める。するとすっっと前の記述をもってくると

と書ける。だから、
となる。だから
にあてはめると

と書ける...!*28
- ガウス分布の場合
ガウス分布の式の の肩にのってる式が二次式だから指数型分布族の式と比べて、とりあえず二次の項と一次式を別々に分けて書くことを考えれば、
の肩にのってる式が二次式だから指数型分布族の式と比べて、とりあえず二次の項と一次式を別々に分けて書くことを考えれば、
とできた。
一般線形モデル( generalized linear models )の構築*29
一般線形モデルの形を導出するために、以下の仮定をおく。
 とする
とする
- つまり、
 が与えられたらはなんらかの指数型分布族の分布をもつ
が与えられたらはなんらかの指数型分布族の分布をもつ
- つまり、
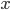 が与えられたとして、目的はが与えられたときの
が与えられたとして、目的はが与えられたときの の平均値を予測すること。
の平均値を予測すること。
 は学習を通してパラメータを変更していき、
は学習を通してパラメータを変更していき、![{h(y) = E[y|x]}](https://cdn-ak.f.st-hatena.com/images/fotolife/m/misos/20201118/20201118154842.png) を満たすようになってほしい。
を満たすようになってほしい。
- 自然パラメータと入力値は線形の関係があり
 となる
となる
These three assumptions/design choices will allow us to derive a very elegant class of learning algorithms, namely GLMs.
(cs229-notes1.pdfより引用)
どうやらすごくエレガントな学習アルゴリズムのクラスがこっから導かれるという。
一般線形モデルでの最小二乗法
最小二乗法(Ordinary Least Squares)は一般線形モデルの特別な場合。今、目標変数(ただし一般線形モデルの文脈ではこれを応答変数*30と呼ぶ)は連続的であると仮定する。そしていま指数型分布族 としてが与えられたらはこのガウス分布に従うとする。ここで少し前に書いた奴をみて
としてが与えられたらはこのガウス分布に従うとする。ここで少し前に書いた奴をみて
※少し前に書いた奴
 だと分かる。よって
だと分かる。よって
![{
h_{\theta} (x) = E[y|x;\theta] = \mu = \eta = \theta^T x
}](https://cdn-ak.f.st-hatena.com/images/fotolife/m/misos/20201118/20201118145140.png)
と(仮定などを利用して)記述できる。
一般線形モデルでのロジスティック回帰
ロジスティック回帰を使った文脈では だったからポアソン分布を使おうと考えるのは自然。ここで(復習のために何も見ずに書くと)
だったからポアソン分布を使おうと考えるのは自然。ここで(復習のために何も見ずに書くと)
みたいに書ける。この式で 。今、
。今、 とすれば、
とすれば、![{ E[y|x;\theta] = \phi}](https://cdn-ak.f.st-hatena.com/images/fotolife/m/misos/20201118/20201118152359.png) だから
だから
![{
h_{\theta} (x) = E[y | x; \theta] = \phi = \frac{1}{1 + e^{-\eta}} = \frac{1}{1 + e^{-\theta^T x}}
}](https://cdn-ak.f.st-hatena.com/images/fotolife/m/misos/20201118/20201118145132.png)
と導ける。ここまできてやっとなんで二値のクラスわけ問題でなんでシグモイド関数が出てきたかすこし納得する。 は正にシグモイド関数...!
は正にシグモイド関数...!
ソフトマックス回帰*31*32
これは映像の講義ではやっていない。簡単に言うとシグモイド関数の多変量バージョン。つまり?いままで だったのが
だったのが になるということ。ということは今まで二値だからベルヌーイ分布だったのだからk値だから多項分布を使うのも自然。しかしここでもう一工夫必要らしい。
になるということ。ということは今まで二値だからベルヌーイ分布だったのだからk値だから多項分布を使うのも自然。しかしここでもう一工夫必要らしい。
さっきはニクラスに分けるだけだから だけでよかったけど今度はになる変数一つだけではkこのクラスのどこに所属するかが分からない。はじめに
だけでよかったけど今度はになる変数一つだけではkこのクラスのどこに所属するかが分からない。はじめに を考えるのが普通だけど実際にそんな場合分けができるようなシグモイド関数見たいな連続的なグラフを試しに想像してみるとなんか階段状にくねくねしててヤバそう、これまでの結果を使ってなんとかできないかを考える。すると
を考えるのが普通だけど実際にそんな場合分けができるようなシグモイド関数見たいな連続的なグラフを試しに想像してみるとなんか階段状にくねくねしててヤバそう、これまでの結果を使ってなんとかできないかを考える。すると を定義してjクラスに所属するときは第j要素のみが1の単位ベクトル
を定義してjクラスに所属するときは第j要素のみが1の単位ベクトル を使うと考えるのは自然。
を使うと考えるのは自然。

引用:cs229-notes1_pdf(27_30ページ)
さらに以下の記号を導入する。
- 指示関数(indicator function*33 )、要は直後の括弧の内容が真なら1,偽なら0をとる関数
- 各クラスに属する確率を示すパラメータは
 と書くと
と書くと と書くことができる。
と書くことができる。
we can also write the relationship between
and
. (Before you continue reading, please make sure you understand why this is true!)
引用元:cs229-notes1.pdf
ことを確認する。そして以下の式変形。

引用:notes1_pdf(28_30ページ)
ここで

の変形はベルヌーイ分布の場合の変形と全く同じ方法。結果をみてもベルヌーイ分布の場合の一般化バージョンと分かる。*34。以降は講義資料*35を参照。
(第四回おわり)
第五回授業メモ
生成モデルと識別モデルの違い*36*37
について。そして後ほどベイジアン。今回からなるべく板書も灰色の枠に記述することに。*38
Discriminative and Generative learning algorithm(識別モデルと生成モデル)
はじめ〜23:00までの映像の内容
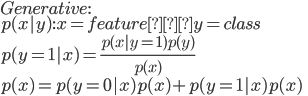
板書:映像6:10頃
板書:映像9:10頃
So back where we're fitting logistic regression models or generalized linear models, we're always modeling
, and that was the conditional likelihood, okay? In which we are modeling [tex:{p(y^i | x^i)} , whereas, now, generative learning algorithms, we are going to look at the joint likelihood which is [tex:{p(y^i , x^i)} , okay?(映像 17:00)
これまではが与えられたときの条件付き確率分布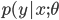 を考えてきた。例えばロジスティック回帰はクラスを二つにわけるときに入力を一つの空間に写像してそれらを分ける境界線を探して一本線を引く。だけど違うアプローチもある。例えば象(1)と犬(0)を区別するときに、象と犬それぞれに別々のモデルを作って入力データはどちらに”似ている”かを見てクラスを判断することもできる。
を考えてきた。例えばロジスティック回帰はクラスを二つにわけるときに入力を一つの空間に写像してそれらを分ける境界線を探して一本線を引く。だけど違うアプローチもある。例えば象(1)と犬(0)を区別するときに、象と犬それぞれに別々のモデルを作って入力データはどちらに”似ている”かを見てクラスを判断することもできる。
前者(ロジスティック回帰やパーセプトロン)は識別モデル、後者は生成モデルと呼ばれるクラスに大別される。前者は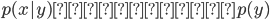 をモデル化しようとするのに対して後者は
をモデル化しようとするのに対して後者は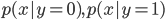 を別々にモデル化する。生成モデルでは
を別々にモデル化する。生成モデルでは

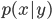 をモデル化
をモデル化
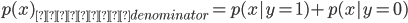
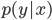 を求めるにあたり、分母を計算しなくていいのは今は上の式を最大化する
を求めるにあたり、分母を計算しなくていいのは今は上の式を最大化する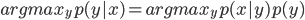 とできるためと分かる。
とできるためと分かる。Gaussian discriminant analysis*42
以下の質問で紹介されていたページをとりあえず見る、分かりやすかった。
machine learning - What is a Gaussian Discriminant Analysis (GDA)? - Cross Validated
Discriminant Functions For The Normal(Gaussian) Density - Rhea
Discriminant Functions For The Normal(Gaussian) Density - Part 2 - Rhea
△ガウス分布に関する導入
多変数正規分布は結局
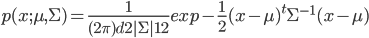
と書くことができる。そして分散共分散行列を導入。たとえば確率変数ベクトル に対して
に対して
![{
Cov(Z) \\
= E[ (Z - E(Z) )(Z - E(Z) )^T] \\
= E(ZZ^T) - (E(Z))(E(Z))^T \\
}](https://cdn-ak.f.st-hatena.com/images/fotolife/m/misos/20201118/20201118144507.png)
と書くことができる。ここで資料より
You should be able to prove to yourself that these two definitions are equivalent.
とあるので確認する。
![{
E[Z E(Z)^T] = E[ \sum z_i (E(z_i)) ] = \sum z_i E(z_i)E(z_i) \\
E[ \sum z_i (E(z_i)) ] = E[ \sum (E(z_i)) z_i ] = E[ E(Z)Z^T]
}](https://cdn-ak.f.st-hatena.com/images/fotolife/m/misos/20201118/20201118144526.png)
と確認。そして今、上記のような多変数ガウス分布上の確率変数ベクトルはとなる。

引用元:cs229-notes2_pdf(3_14ページ)
上の図の一番ひだりが分散共分散行列が単位行列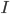 、つぎが
、つぎが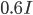 ,一番右が
,一番右が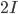 の場合。つまり値が大きいほど平たい形状になるらしい。そして今度は対角要素以外の値を入れていくと
の場合。つまり値が大きいほど平たい形状になるらしい。そして今度は対角要素以外の値を入れていくと

引用;cs229-notes2_pdf(3_14ページ)
 がかわるとグラフの頂点の位置がかわる。この共分散行列と平均ベクトルの二つで多変数ガウス分布は定義される。
がかわるとグラフの頂点の位置がかわる。この共分散行列と平均ベクトルの二つで多変数ガウス分布は定義される。
The Gaussian Discriminant Analysis model(GDAモデル)
GDAモデルとロジスティック回帰の関係*43
GDAの特徴

ナイーブベイズモデル*44*45
ナイーブベイズ分類器を頑張って丁寧に解説してみる - Qiita
モデル化するために以下の仮定(Naive Bayes (NB) assumption)を仮定する。
’s are conditionally independent given
引用:cs229-notes2.pdf
この結果得られるクラス分類機を単純ベイズ分類機(Naive Bayes classifier)と呼ぶ。
書きかけ。
参考文献と関連ページ
- Stanford engineering everywhere artificial intelligence | machine learning
- 記事の中の図の引用元
- Stanford engineering ever に関するFAQ
- 元サイトの著作権表示 Attribution 3.0 United States (CC BY 3.0 US)
- FrontPage - 機械学習の「朱鷺の杜Wiki」
- 上記のページおよびpdf以外の参考文献や関連ページ
*4:引用:Algorithmic learning theory - Wikipedia, the free encyclopedia
*6:http://en.wikipedia.org/wiki/Stochastic_gradient_descent
*8:http://www.mit.edu/~wingated/stuff_i_use/matrix_cookbook.pdf
*9:cs229-notes1.pdf
*10:Econometric Theory/Ordinary Least Squares (OLS) - Wikibooks, open books for an open world
*11:Widrow-Hoffの学習規則 - 機械学習の「朱鷺の杜Wiki」
*12:https://upo-net.ouj.ac.jp/tokei/xml/k3_04012.xml
*14:第15回 分類問題ことはじめ:機械学習 はじめよう|gihyo.jp … 技術評論社
*15:cs229-notes1.pdf 16p
*16:https://inst.eecs.berkeley.edu/~ee127a/book/login/l_lqp_apps_class.html
*19:
*23:講義資料:cs229-notes1.pdf page22より
*24:Stanford Engineering Everywhere | Artificial Intelligence | Machine Learning より
*25:Exponential family - Wikipedia, the free encyclopedia
*27:http://www.ntrand.com/jp/bernoulli-distribution/
*28:関連文献;http://statmath.wu.ac.at/courses/heather_turner/glmCourse_001.pdf
*29:https://www.youtube.com/watch?v=nLKOQfKLUks&feature=PlayList&p=A89DCFA6ADACE599&index=3 /40:00頃から
*30:Explanatory and Response Variables
*31:Softmax Regression - Ufldl
*32:ソフトマックス関数 - 機械学習の「朱鷺の杜Wiki」
*34: に注目して見るとわかる
に注目して見るとわかる
*35:http://see.stanford.edu/materials/aimlcs229/cs229-notes1.pdf の最後の2ページ
*36:たまたま見つけた質問;machine learning - Generative vs. discriminative - Cross Validated
*37:Musings about Machine Learning, Technology and Teaching: Discriminative vs. generative learning: which one is more efficient?
*38:講義資料: see.stanford.edu/materials/aimlcs229/cs229-notes2.pdf
*40:class priorsと呼ぶ
*42:machine learning - What is a Gaussian Discriminant Analysis (GDA)? - Cross Validated
*43:映像:20:00頃より
*45:Naive Bayes classifier - Wikipedia, the free encyclopedia