参考文献
- 数理統計演習 (サイエンスライブラリ―演習数学) 著者名: 国沢清典 羽鳥裕久
第四、五章を参考にしています。以下は同著者の本です。上記の本は結構古いのでおそらく販売していません。この記事でのページ記述は上記の本の内部でのページ番号です。
 |
 |
推定
母集団からランダムに抽出される標本より母集団の統計的特性に関する推定を行うための数学的理論(p97)
点推定
はじめに言葉の定義から。
言葉の定義
点推定
母数のパラメータの推定値を求めること。パラメタが連続変数ならば厳密には一致する確率は0。
点推定 - Wikipedia
推定値
点推定によって母数を推定した値
一致推定量
推定値が母数に確率収束するならば、その推定値は一致推定量と呼ぶ。以下は確率収束の定義の項目、だけどこの辺を問いに出すのは理学部系だけな気もする。
確率変数の収束 - Wikipedia
不偏推定量
推定値も確率変数を元にして決まるものだから、推定する度に変化する。つまり推定値も確率変数の一つ。だから推定値の分布もあるはずだしその平均や分散もある。推定値の平均が母数に一致するとき、その推定値を不偏推定量という。
標本平均
標本の平均。以下記号は統一して 。
。
標本分散
標本の分散。以下記号は統一して
不偏分散
標本分散は不偏推定量でないから、それをもとにして作った母分散に関係する不偏推定量。以下記号は統一して
標本分散と不偏分散に関係する補足
まず、標本平均は母平均の不偏推定量であることは大数の法則そのものからわかる。
大数の法則 - Wikipedia
そして、標本分散については
この最後の式が母分散に確率収束するから標本分散は一致推定量。
母分散の不偏推定量については今は飛ばします、時間ある時に記述。
となる。よって推定値の平均が母分散に一致するために係数(n-1)をnにする必要があるとわかり不偏分散 が求まった。
が求まった。
超適当例題
データ: 10 20 30 40 50
このとき、平均と分散を推定。
標本平均:
標本分散:
不偏分散:
推定値として、標本平均と不偏分散をとる。
http://www.tamagaki.com/index.php
区間推定
母数の含まれる区間を定めて、ある値α(有意水準)を定める。母数が含まれる確率がαとなるような区間をもとめることを区間推定と言う。
χ二乗分布とt分布の式の形に付いては推定するだけなら必要ない(しかし、推定になぜその分布表を使うのかを理解するためには当然必要知識で正直理解してないとすぐに忘れるかミスする気がするが時間ない)ので略。詳細は数理統計ハンドブック等参照。
- 分散が既知の正規分布もつ母集団の母平均の区間推定
有意水準αを定めたとする。標本平均 と記述する。このとき母集団は正規分布に従うのだから、標本平均
と記述する。このとき母集団は正規分布に従うのだから、標本平均 は
は に従う。つまり
に従う。つまり だから
だから 。さらに変形すれば
。さらに変形すれば である。(ここで記号~は”以下の分布に従う”という意味)なので、
である。(ここで記号~は”以下の分布に従う”という意味)なので、
と式変形できる、最後の式こそが求めるべき区間であり、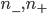 は有意水準によって決まる値で正規分布表から読み取ればよい。この最後の式
は有意水準によって決まる値で正規分布表から読み取ればよい。この最後の式 には母分散σが現れているから、分散が既知でないならば違う方法が必要ではないかと察しが付く。
には母分散σが現れているから、分散が既知でないならば違う方法が必要ではないかと察しが付く。
- 分散が未知の正規分布もつ母集団の母平均の区間推定
標本数がnならば自由度n-1のt分布に従う。このとき推定される区間は

であり、Sは標本分散、は有意水準によって決まる値でt分布表から読み取る。ここでデータ数が少ない(n<30)ならば不偏分散を用いるべきであり不偏分散sのもとめかたを思い出せば だった。つまり
だった。つまり であって
であって 。これを代入して、
。これを代入して、

がデータ数が少ないときに用いるべき区間。
- 以下Tamagaki Dental Clinicさんのページがこれよりはるかにわかりやすいです。
 )の母分散の区間推定
)の母分散の区間推定

 は
は の値、
の値、 の値である。
の値である。母平均の差の推定区間の導出
おぼえてても忘れるから導き出せるようにする。
P139を参考
二つの正規母集団があって分散が未知だけれども等しいと分かっているとする。
それぞれ と記述して、
と記述して、 からは
からは のデータを、
のデータを、 からは
からは のデータを得られたする。このとき、
のデータを得られたする。このとき、
は自由度m+n-2のt分布に従うことが知られている。
ことを利用して信頼区間を導き出す。上の式がm+n+2の自由度のt分布に従うことが分かっているのだから有意水準αがあれば
![{
Pr(t_{-} < \frac{(\bar{x}-\bar{y}) - (\mu_1 - \mu_2)}{\sqrt{[\frac{mS_1^2 + nS_2^2}{m+n-2} (\frac{1}{m} + \frac{1}{n} )]}} < t_{+}) < \alpha
}](https://cdn-ak.f.st-hatena.com/images/fotolife/m/misos/20201118/20201118144043.png)
となるような区間をつくる をt分布表から読み取ることができる。あとはこの式を
をt分布表から読み取ることができる。あとはこの式を が挟み込まれるように変形して
が挟み込まれるように変形して
と求めることができる。
検定
母集団に対する仮説の正否を標本を用いて検定するための手法を論ずる。
言葉の定義
危険率
有意水準とも言う。以下では と記述。つまり、帰無仮説によって決まる棄却域に得られた標本(のセット)が入る確率が以上となるならば帰無仮説を棄却する。棄却されることは対立仮説が正しいと述べている分けではないことに注意。
と記述。つまり、帰無仮説によって決まる棄却域に得られた標本(のセット)が入る確率が以上となるならば帰無仮説を棄却する。棄却されることは対立仮説が正しいと述べている分けではないことに注意。
両側、片側検定
省略。
その他
検出力や尤度比検定とかは数理統計ハンドブックが詳しいと思った(粉みかん)。
適当例題
- 1.
 の分布をもつ母集団からnこの標本を得た。今、分散
の分布をもつ母集団からnこの標本を得た。今、分散 は既に知っているとして標本から母集団の平均の値に関する帰無仮説
は既に知っているとして標本から母集団の平均の値に関する帰無仮説  を検定する手法は?
を検定する手法は?
初めに検定するのだから有意水準が定められていないといけないのでとりあえず有意水準を[:{\epsilon}]とする。
次に、帰無仮説  に対応する対立仮説帰無仮説
に対応する対立仮説帰無仮説  を立てる。
を立てる。
そして最後に帰無仮説 を棄却するかを決定する検定方式を決定する。有効推定量である標本平均の分布を求めたときの式を思い出すと

という区間が定められて、正規分布が左右対称であること(正規分布の式の形からわかる)を思い出せば

が成り立たないなら棄却する方式をとる。
本当は検定方式の決定には第二種の過誤をする率を最低にする、とかいろいろ調べないといけないが数理統計の試験ではそこは問われないからいまはパス。だけど工学部の専門の確率の試験では試験で聞かれました。一様最強力検定やネイマンピアソン定理など、だけど一般教養dの試験では普通聞かれない、はず。
- 2.の分布をもつ母集団からnこの標本を得た。今、分散は分からないとして標本から母集団の平均の値に関する帰無仮説 を検定する手法は?
分散は未知だからもう標本分散か不偏分散を使うしかないことはわかる。そして、分散が未知の時の信頼区間の式を思い出すと検定にはt分布を用いることが分かる。

なのだから、

が成り立たないのならば棄却する。
つまり、

なら棄却する、を検定方式とする。
- 3. データが10,11,12,13,14(つまりn=5)とある時にこの母集団の平均を12としてよい?
初めに帰無仮説  と対立仮説
と対立仮説  を決定する。
を決定する。
次にデータの標本平均と標本分散を求める。その値を とする。
とする。
そして、有意水準αを定めて(普通は問題に指示されている)、が真ならば棄却しない。
- 4.もともと平均が12である母集団に操作を加えてデータをとるとデータが9,10,11,12,13となったとする。操作にデータの平均値を下げる効果があったと言える?有意水準はαとする。
初めに帰無仮説 と対立仮説  を決定する。対立仮説の形から片側検定と分かる。
を決定する。対立仮説の形から片側検定と分かる。
つまり、

が成り立つならば帰無仮説を棄却して対立仮説を採択する。もしも帰無仮説 と対立仮説  という問題設定ならばもちろん
という問題設定ならばもちろん

が成り立つならば帰無仮説を棄却して対立仮説を採択することになる。上記ではt分布の自由度は5-1=4.
- 5.正規母集団の分散に関する検定を行う。標本
 から帰無仮説
から帰無仮説  を検定する手法は?
を検定する手法は?
初めに対立仮説
分散の信頼区間を求めるには、二乗和に関する分布が必要であってΧ二乗分布を導入した。そして、その信頼区間は有意水準をαとして

であったことを思い出す。また以下では とする。
とする。
※Χ二乗分布が二乗和に関する分布であることを忘れなければ、 であり、この式を変形すると
であり、この式を変形すると だから信頼区間の式が
だから信頼区間の式が で記述されることが分かる。
で記述されることが分かる。
だから検定は

ならば棄却しない。
- 6.データが9,10,11,12,13となったとするときに、母分散はどの程度といっていい?
もとの母集団の分布をと仮定して帰無仮説と対立仮説 ととする。有意水準はαとする。
初めに標本分散を求めるために標本平均を求めて、それを とする。その標本平均を用いて標本分散を計算する、そしてそれを
とする。その標本平均を用いて標本分散を計算する、そしてそれを とする。そして
とする。そして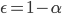 を用いて区間
を用いて区間 が真ならば棄却しない。
が真ならば棄却しない。
- 7.二つの母集団
 から標本
から標本 を、母集団
を、母集団 から標本
から標本 を得たときにこの二つの母集団の分散が等しいかを検定する手法は?
を得たときにこの二つの母集団の分散が等しいかを検定する手法は?
これを解こうとして分散比の推定についての記述をこの記事に書いてないことに気づいたけど時間内ので飛ばします、すいません。
平均と異なり、分散の差をとろうとすると行き詰まってしまうのは分散の式が二乗和であって、分散の推定に関係する分布Χ二乗分布やF分布にあてはめることができないからだと気づく(分散の差を二乗和の式として書き表すことができない)。そして比率 ならば自由度(m-1,n-1)F分布を利用することができる。
ならば自由度(m-1,n-1)F分布を利用することができる。
つまりと定めたとして が成り立つならば、帰無仮説を棄却することはできない。
が成り立つならば、帰無仮説を棄却することはできない。
- 8.あるデータ10,11,12,13,14(つまりn=5)とデータ10,10,12,13,13,15(つまりn=6)がある時にこの二つのデータの元となる母集団の分散は等しいと言える?
有意水準をαとする。また前者のデータを と書く。
と書く。
まず初めに帰無仮説と対立仮説  と
と を立てる。次にF分布をつかって分散比の推定をしたことを思い出せば、分散比を求めるために
を立てる。次にF分布をつかって分散比の推定をしたことを思い出せば、分散比を求めるために
- 二つのデータの標本平均
 を求め、
を求め、 - 標本平均を用いて標本分散
 を求め、
を求め、 - 比率
 を求め、
を求め、 - F分布上でに対応する点
 を求める
を求める
最後に、区間()に が含まれていないならば帰無仮説を棄却して対立仮説を採択する。
(適合度検定、回帰分析、分散分析などは省略。)