情報源及び出典、参照元
- Stanford engineering everywhere artificial intelligence | machine learning
- Stanford School of Engineering - Stanford Engineering Everywhere
- 講師:Andrew Ng (敬称略) 、著作権表示及び授業関連資料は上記サイトを参照してください。
- この記事の中の図の引用元
- Stanford School of Engineering - Stanford Engineering Everywhere
- それぞれの引用した図で、引用元(上記ページのpdfファイル名)を明記します。
- Stanford engineering ever に関するFAQ
- http://see.stanford.edu/see/faq.aspxを参照して下さい。
- 元サイトの著作権表示 Attribution 3.0 United States (CC BY 3.0 US) の日本語訳はここにありますが、誤解が無いように必ず英語ページを見てください。そして、この記事も同様にCC BY 3.0 USに従います。
※上記のページおよびpdf、上記以外の参考文献や関連ページを注釈の形でページ末尾に改めて記載します。
関連する文献
 |
 |
 |
黄色いのがいいです。
第五回授業メモ
生成モデルと識別モデルの違い*1*2
について。そして後ほどベイジアン。今回からなるべく板書も灰色の枠に記述することに。*3
Discriminative and Generative learning algorithm(識別モデルと生成モデル)
はじめ〜23:00までの映像の内容
- 識別モデル
 を学習する
を学習する- 言い換えると、[tex{h_{\theta}(x) \in \{0,1\}}]を直接学習する
その一方、
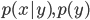 をモデル化
をモデル化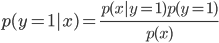
教師あり学習で観測データを分類するにあたって、まず観測データの属性を適当に組み合わせた判別関数を生成する。未知のデータは、この判別関数で分類する。これを識別モデルという。
一方、観測データを生成する確率分布を想定し、観測データからその確率分布を推定する方法を生成モデルと呼ぶ。
引用元:統計的機械学習 | 中川研究室
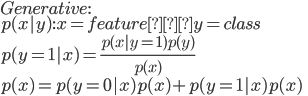
板書:映像6:10頃
板書:映像9:10頃
So back where we're fitting logistic regression models or generalized linear models, we're always modeling
, and that was the conditional likelihood, okay? In which we are modeling [tex:{p(y^i | x^i)} , whereas, now, generative learning algorithms, we are going to look at the joint likelihood which is [tex:{p(y^i , x^i)} , okay?(映像 17:00)
これまでは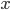 が与えられたときの条件付き確率分布
が与えられたときの条件付き確率分布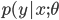 を考えてきた。例えばロジスティック回帰はクラスを二つにわけるときに入力を一つの空間に写像してそれらを分ける境界線を探して一本線を引く。だけど違うアプローチもある。例えば象(1)と犬(0)を区別するときに、象と犬それぞれに別々のモデルを作って入力データはどちらに”似ている”かを見てクラスを判断することもできる。
を考えてきた。例えばロジスティック回帰はクラスを二つにわけるときに入力を一つの空間に写像してそれらを分ける境界線を探して一本線を引く。だけど違うアプローチもある。例えば象(1)と犬(0)を区別するときに、象と犬それぞれに別々のモデルを作って入力データはどちらに”似ている”かを見てクラスを判断することもできる。
前者(ロジスティック回帰やパーセプトロン)は識別モデル、後者は生成モデルと呼ばれるクラスに大別される。前者は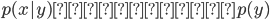 をモデル化しようとするのに対して後者は
をモデル化しようとするのに対して後者は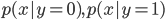 を別々にモデル化する。生成モデルでは
を別々にモデル化する。生成モデルでは


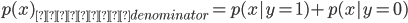
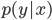 を求めるにあたり、分母を計算しなくていいのは今は上の式を最大化する
を求めるにあたり、分母を計算しなくていいのは今は上の式を最大化する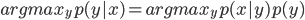 とできるためと分かる。
とできるためと分かる。Gaussian discriminant analysis*8
以下の質問で紹介されていたページをとりあえず見る、分かりやすかった。
machine learning - What is a Gaussian Discriminant Analysis (GDA)? - Cross Validated
Discriminant Functions For The Normal(Gaussian) Density - Rhea
Discriminant Functions For The Normal(Gaussian) Density - Part 2 - Rhea
△ガウス分布に関する導入
多変数正規分布は結局
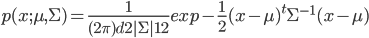
と書くことができる。そして分散共分散行列を導入。たとえば確率変数ベクトル に対して
に対して
![{
Cov(Z) \\
= E[ (Z - E(Z) )(Z - E(Z) )^T] \\
= E(ZZ^T) - (E(Z))(E(Z))^T \\
}](https://cdn-ak.f.st-hatena.com/images/fotolife/m/misos/20201118/20201118144507.png)
と書くことができる。ここで資料より
You should be able to prove to yourself that these two definitions are equivalent.
とあるので確認する。
![{
E[Z E(Z)^T] = E[ \sum z_i (E(z_i)) ] = \sum z_i E(z_i)E(z_i) \\
E[ \sum z_i (E(z_i)) ] = E[ \sum (E(z_i)) z_i ] = E[ E(Z)Z^T]
}](https://cdn-ak.f.st-hatena.com/images/fotolife/m/misos/20201118/20201118144526.png)
と確認。そして今、上記のような多変数ガウス分布上の確率変数ベクトル は
はとなる。

引用元:cs229-notes2_pdf(3_14ページ)
上の図の一番ひだりが分散共分散行列が単位行列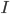 、つぎが
、つぎが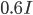 ,一番右が
,一番右が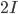 の場合。つまり値が大きいほど平たい形状になるらしい。そして今度は対角要素以外の値を入れていくと
の場合。つまり値が大きいほど平たい形状になるらしい。そして今度は対角要素以外の値を入れていくと

引用;cs229-notes2_pdf(3_14ページ)
 がかわるとグラフの頂点の位置がかわる。この共分散行列と平均ベクトルの二つで多変数ガウス分布は定義される。
がかわるとグラフの頂点の位置がかわる。この共分散行列と平均ベクトルの二つで多変数ガウス分布は定義される。
The Gaussian Discriminant Analysis model(GDAモデル)
University of Southern Denmark の講義資料を見つける、機械学習の導入を一通りしているらしく後ほど参照するかもしれない。なぜが日本語のWikiは無かった。Rの解説やパーセプトロンのイメージ動画なども下記ページで公開している。すごいい。
Syddansk Universitet - Wikipedia, den frie encyklopædi
DM825 - Introduction to Machine Learning
授業内容にそってクラス分類問題を考える。入力値は連続な値をとるとする。GDAモデルを使うことにすると、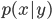 は多変数ガウス分布になって
は多変数ガウス分布になって
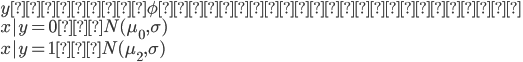
と目標値ごとに別々のモデルを立てる(のが生成モデル!識別モデルでは一つの分布にある”境界線”を引いてそれで分けていた...!)。この分布を式で表現すると
となる。これらのモデルを決定づけるパラメータは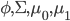 で(ただし、簡単のために分散共分散行列は共通)あり、このときの尤度関数は
で(ただし、簡単のために分散共分散行列は共通)あり、このときの尤度関数は
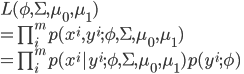
※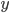 はパラメータ
はパラメータ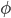 だけで分布が決定する
だけで分布が決定する
ずっと前にやったようにこれを最大化する値を探そうとしてもデータ数が大きいと尤度関数=ほぼ0みたいなことになってしまうので尤度関数の対数をとって
とした式が極大になる点を探す。
を微分していく。結果として

引用:cs229-notes2.pdf page6
GDAモデルとロジスティック回帰の関係*9
映像がわかりやすく略します。
GDAの特徴

※逆は必ずしも言えない
注意する点は、以上から「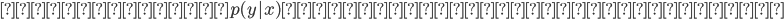 」という仮定よりも「
」という仮定よりも「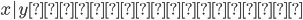 」といった方が強い仮定になる。そしてさらに一般化して
」といった方が強い仮定になる。そしてさらに一般化して
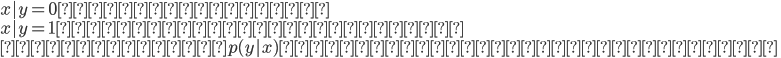
である。ここから二つめの生成モデルを紹介。
ナイーブベイズモデル*10*11
ナイーブベイズ分類器を頑張って丁寧に解説してみる - Qiita
二つめの生成モデル。モデル化するために以下の仮定(Naive Bayes (NB) assumption)を仮定する。
’s are conditionally independent given
引用:cs229-notes2.pdf
この結果得られるクラス分類機を単純ベイズ分類機(Naive Bayes classifier)と呼ぶ。この仮定を設けることによって
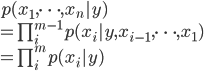
と書けるようになる。講義中の講師Ng氏の例に沿って言えば「スパムメールの分類をするとして一通目のメールがスパムだったとして二通目がスパムメールであるかどうかは一通目の結果とは独立して考える」。このモデルを決定するパラメータは
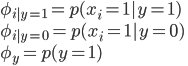
の三つ。(講義53:00ころ)
そして尤度関数は
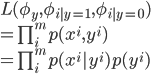

引用元:cs229-notes2.pdf page10
参考文献と関連ページ
- Stanford engineering everywhere artificial intelligence | machine learning
- 記事の中の図の引用元
- Stanford engineering ever に関するFAQ
- 元サイトの著作権表示 Attribution 3.0 United States (CC BY 3.0 US)
- FrontPage - 機械学習の「朱鷺の杜Wiki」
- DM825 - Introduction to Machine Learning
- 上記のページおよびpdf以外の参考文献や関連ページ
*1:たまたま見つけた質問;machine learning - Generative vs. discriminative - Cross Validated
*2:Musings about Machine Learning, Technology and Teaching: Discriminative vs. generative learning: which one is more efficient?
*3:講義資料: see.stanford.edu/materials/aimlcs229/cs229-notes2.pdf
*4:http://ja.wikipedia.org/wiki/%E3%83%99%E3%82%A4%E3%82%BA%E3%81%AE%E5%AE%9A%E7%90%86
*6:class priorsと呼ぶ
*8:machine learning - What is a Gaussian Discriminant Analysis (GDA)? - Cross Validated
*9:映像:28:00頃~33:00
*11:Naive Bayes classifier - Wikipedia, the free encyclopedia