情報理論のメモ
http://www.t.kyoto-u.ac.jp/syllabus-s/?mode=subject&lang=ja&year=2014&b=6&c=91200
主に授業の内容と上記参考文献の演習問題の回答についてのメモ。正しいかどうかはわからないので自己責任で。走り書きなので細かい定義はすべてかっ飛ばしている、だから記事もあんまり長くないし内容もない感じ。講義でのメモは灰色枠。

第2章 エントロピー,相対エントロピー,相互情報量



定義


そして のエントロピーは
のエントロピーは のエントロピーとが決まっている時の
のエントロピーとが決まっている時の のエントロピーの和と考えると
のエントロピーの和と考えると

は納得の行く等式。成り立つ理由は

だから。両辺に条件をつけた

も言える。
- 相互情報量(カルバックライブラー距離)

と記述する。明らかに0なのは二変数が独立しているとき。式を展開して

が言える。
- チェイン則

これは全体のばらつきは のばらつき、のばらつきを求めたからを決め打ちしたときの
のばらつき、のばらつきを求めたからを決め打ちしたときの のばらつき、...と足していくということだと思う。そして直感にあっている。
のばらつき、...と足していくということだと思う。そして直感にあっている。
- Jensen's inequarity
(要約すると) が下に凸な関数で成り立つ。
が下に凸な関数で成り立つ。
証明:
参考文献に記載あり。それ以外では関数を平均まわりでテイラー展開して二次以降の項を無視、そのあと両辺の平均をとれば式を示せるはず。この不等式は相互情報量が0以上であることの証明に利用するために必要。
- データ処理不等式
データは加工すればするほど、もとのデータを予測しにくくなることを数式で示す。マルコフ連鎖に付いては省略、Wikipedia参照*2。 などと書く。
などと書く。
が成り立つとき

が成り立ち、これをデータ処理不等式と呼ぶ。
証明:

がなりたつ、だけど今マルコフ連鎖であるという仮定があるから 、さらに相互情報量は非負の値をとるからデータ処理不等式が成り立つ。
、さらに相互情報量は非負の値をとるからデータ処理不等式が成り立つ。
- ファノの不等式

 通信路を経過して得られたからを推測した値
通信路を経過して得られたからを推測した値
としたときに、不等式
であり、ここから

が導ける。
理由:
- エントロピーの最大値は1
- ある記号に対して誤りが発生するパターンは
 通り
通り
証明:
後ほど追記予定。
確率変数 を新たに定義する、それは
を新たに定義する、それは

となる確率変数でここで推測したときの入力とその推測が正しいか(を示す確率変数)のばらつき具合をしめす条件つきエントロピーを考える。

と二通りに展開できる。ここで「推測値」と「実際の値」が条件についていたらそれが外れているかどうかがわかるから である。最後の不等式は条件付きエントロピーは条件なしより大きくなることはないこと、エントロピーを最大にするのは一様分布であり誤りかたは
である。最後の不等式は条件付きエントロピーは条件なしより大きくなることはないこと、エントロピーを最大にするのは一様分布であり誤りかたは 個あることから分かる。
個あることから分かる。
- 相互情報量は0以上
証明:

演習問題2.1
(a)
(b)同じ。
演習問題2.2

の式を考える、もしもxとyが一対一に対応していれば、y=f(x)となるxはyを決めれば一つに決まる。また、

である。はじめの不等式はlogが増加関数であることから、二つ目の等式は
 を代入すれば得られる。
を代入すれば得られる。
以上の式を用いると、Xのエントロピーについて、
となる。この不等式の等号が成り立つのは、
で等号が成り立つときのみで、それはxとyが一対一に対応しているとき。よって解答は(a) H(X) = H(Y) (b) H(X) => H(Y) となる。
演習問題2.3

上の式を最小にする時、

が成り立つ、この式の最小値はp=0,1の時の0である。

となる。
演習問題2.4
演習問題2.5
H(Y|X)=0ということは、Xが決まると曖昧さが全くなくYが決まるということ、直感的には。式で書いて証明すると、

ここでもしも、YがXの関数でないならあるx'が存在して、それに対応するy’、y''が存在する。このようなx',y',y''がある時、上の式が0にならないことを示せば背理法で問が正しいことを示せる。
ここで、上の式のサメンション(Σ)について、特にx'に注目すると

という項とp(x')との積の項がある。p(x')>0と仮定しているのでこの式が0でないと、H(Y|X)=0ではない。そして、p(y'|x')>0,p(y''|x')>0と仮定しているので成り立たない。
演習問題2.06

となるような例を作る。
(a) Zの条件がついたら情報量が下がるのだからZの値とX、Yの値に関連があるはず。よって必ずY=Z、Y=Xとなる時、Zが分かっている条件だと何もあたらしい情報がなく

となる。
(b)こんどはZが分かっている時の方が相互情報量がおおい、つまりZがXとYの情報の”共通部分”に関する情報をもっている。
簡単にするためにXとYは全く独立とすれば、 .
.
そして Z=X * Y とすればいい。
演習問題2.11
a

とは同一の文応だからエントロピーも同じであり

b

だから

が0未満になることはない.
c
aの式より二変数の相互情報量が0の時。
それは二変数が同一分布で独立な時。
d
aの式より が0の時。それは二変数が等しいとき、もっと一般的には二変数が一対一対応しているとき。
が0の時。それは二変数が等しいとき、もっと一般的には二変数が一対一対応しているとき。
演習問題2.14
a H ( Z | X ) = H ( Y | X )

Z = X + Yなのだから、

が成り立つ。このことから、
x、Yが完全に独立な確率変数ならば、 である。この場合、
である。この場合、

となる。
b
との和が常に限られた値しかとらないにもかかわらず、との値が定まらないような分布にする。の分布と の分布が同じになるようにすればいい。
の分布が同じになるようにすればいい。
c
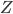 はとの値に依存した確率変数だから、
はとの値に依存した確率変数だから、

は明らか。もっと詳しく記述すると

となる。すべての部分で等号が成り立つためには
「XとYは完全に独立」
「ZはXとYの関数」
である必要がある。
演習問題2.15

演習問題2.29
a

b

c

d

であり、

でここから

よって

となる。
 を最大化するためには
を最大化するためには が最大になる必要がある。そして離散の値をとる確率変数の
が最大になる必要がある。そして離散の値をとる確率変数の




 は最大のところで
は最大のところで
第3章 AEP

大数の法則のエントロピー版のイメージがある。また典型集合という概念を導入する。たとえ0が1より出やすくても「00000」よりも「00100」「01000」「00001」のような列の方がよく出現しそう...、そんな列の集まり。
漸近等分割性(AEP)
もしも確率変数 が独立で同一な分布
が独立で同一な分布 に従うならば
に従うならば

である。 は確率収束*5の意味。
は確率収束*5の意味。
典型集合(typical set)
典型集合 を以下のように定義。
を以下のように定義。

となるような列 の集合。
の集合。
典型集合が満たす性質
むしろ満たすようにうまく定義したように感じる。
 \in \chi^n) \geq 1 - \epsilon}\"/>を満たす十分大きなnが存在する
の要素数は以下である
証明:
ひとつめは定義式の両辺のlogをとって漸近的等分割性を適用するとすぐわかる。
ふたつめはとすればいい。他の性質もはじめに書いた参考文献に記載されている。 これらの性質から典型集合に属していない列の出現確率はnを十分大きくすればによって押さえることができる。つまり、符号の平均長を考えるときに典型集合に属していない符号の長さを(以下でしか出現しないから)無視できるようになる。その結果として一情報源符号あたりの符号の長さは以下であるようにすることができると分かる。
演習問題3.01
マルコフ不等式*6とチェビシェフ不等式*7。
演習問題3.02
[tex:{
\frac{1}{n} \log \frac{p(X^n) p(Y^n) }{p(X^n , Y^n)} \\
= -\frac{1}{n} \log \prod_{k=1}^n \frac{p(X_k) p(Y_k)}{p(X_k , Y_k)} \\
= -\sum \log \frac{1}{n} \frac{p(X_k) p(Y_k)}{p(X_k , Y_k)} \\
->_{n -> \infty} E(-\log \frac{p(X) p(Y)}{p(X, Y)})
}]
そして最後の式は相互情報量の定義の式そのもの。そして相互情報量は二変数が完全に独立のときに0になるのだから問題の与式は1に収束。
演習問題3.04
問題は
と記号を定義する。
a
漸近等分割性から言える。
b
大数の法則*8から
各回の試行において各事象の起こる確率というものが、試行回数を重ねることで、各事象の出現回数によって捉えられるというのが大数の法則の主張するところ
やがて平均に収束することを踏まえると
である。ここからあ以下の条件を満たす十分小さな値と自然数が存在する。
だからこれらをともに満たす集合に属する確率はよって正しい。
c
出現する要素の確率をすべて足したら1になることから
であり、典型集合に含まれる要素の確率は
なのだから、
d
典型集合に含まれる要素の確率は
であり、ある十分大きい実数Mで
となるMが存在することは問bより分かる。よって問cと同じような解き方で(M > M)として
と求められる。
演習問題3.06
であり、
を代入して、
となる。
演習問題3.11
This problem shows that the size of the smallest “probable”set is about *9
a
b
c
第4章 確率過程のエントロピーレート
マルコフ連鎖
説明略。信州大学の資料*10があったのでそれを参考資料としてメモしておく。要は現在の状態になるための遷移確率は直前の状態からのみ決定して、それ以前の過去の遷移(履歴)は全く関係しない。
time invariant
Wikipedia*11には難しいことが書いてあるけれど、現在の文脈においては”添字に関係しない”ということで、ただそれだけ。つまり。 この章の内容はマルコフ連鎖のエントロピーレートの求め方など。めもは省略、だけど大切な内容。
演習問題4.03
条件がついたらもちろんエントロピーは下がりうる。
演習問題4.04
演習問題4.09
データ処理不等式からが言える。この式の両辺を変形すると問題の式が導ける。
(の展開。)
要は元になるデータを加工しまくるほど、元データが何だったかが分かりにくくなる。
演習問題4.11
a
真。なぜならば
b
偽。データ処理不等式の考えからすると元のから離れるほど「当てにくい」ことから真っぽく見える。だけど問題に「マルコフ連鎖である必要は無い(not necessarily Markov)」ところに注目。マルコフ連鎖は直前の状態にのみ依存して現在の状態の確率が決まる。ここを「の状態に依存して現在の状態が決まる」としたとき、この不等式はいつも真とは限らない、と言えるようにしたい。
いつも真では無いことを言えばいいのだからnをある定数kとする。すると「確率変数の値はk個前の状態に依存して\"一意に\"決まる」ような確率過程はこの不等式を満たさないと分かる。
(はによって一意に決定するのだから)
c
真。
ここで条件が増えればエントロピーはさが(りう)ることを示した不等式を用いれば、
このことからnが増加したのに式の値が増えていないことが言える。
d
真。
演習問題4.14
エントロピーレートの式をXについて書き下すと
なのだからエントロピーレートの大小関係は分母のの大小関係が言えればいい。
ここでXを関数によって写像した先がYなのだから、Xが決まればYの値は有限個の候補しかない。よってどんなに対してもと言っていい。Zについても。このことから
演習問題4.15
与式を条件付きエントロピーのチェイン則に従って展開する。*12より成り立つ。
演習問題4.18
a
0? Xは二種類のコインのうちどちらを選んだか。Yはそれを投げる試行を二回行ったこととできまる。
相互情報量の定義の式に当てはめるとこの式を見ると、そもそもコインを選ぶことによってコインの表が出る確率が変わるけれどそのコインを条件付けされたらになるので0.だろう。
b
コイントスの結果とコイントスの順番は関係ないはずだからとする。以上から
c
未回答
演習問題4.32
直感的には。なぜならからだけ離れているから。
演習問題4.33
未回答。
を踏まえて与式の両辺からを引くと
を示せばいい。
追記:
いろいろいじった結果
になる、かも。
第5章 データ圧縮
符号の種類
正則符号
*13より引用すると、
A code is non-singular if each source symbol is mapped to a different non-empty bit string, i.e. the mapping from source symbols to bit strings is injective.
要は情報源の記号それぞれに、別々の符号化が与えられているとき。
一意的復号可能符号
符号の列全体を受け取って、それをもとの記号列にデコードするときにただ一通りにしかデコードできないような符号。
瞬時符号*14
符号の列を先頭から読み取っていきながら、現在までに読み取っている列がなんらかの符号にマッチしているか調べてマッチしたらその場で符号を決めてしまってもいいような符号。
任意の符号語が他のいかなる符号語の接頭部にもなっていないという属性*15
という性質が必ず必要。
ハフマン符号
ハフマン符号 更生法 - Google 検索
クラフト不等式とマクミラン不等式
証明は英語版のWikipediaに記述あり、そしてそれは参考文献に記載されたものと全く同じもの。
Kraft's inequality - Wikipedia, the free encyclopedia
Kraft, Leon G. (1949), A device for quantizing, grouping, and coding amplitude modulated pulses, Cambridge, MA: MS Thesis, Electrical Engineering Department, Massachusetts Institute of Technology.
McMillan, Brockway (1956), \"Two inequalities implied by unique decipherability\", IEEE Trans. Information Theory 2 (4): 115–116, doi:10.1109/TIT.1956.1056818
クラフト不等式
を瞬時符号は満たす。
証明:上記英語Wikipwdia参照。
マクミラン不等式
を一意的復号可能符号は満たす。
証明:上記英語Wikipwdia参照。参考文献の定理5.5.1。
最適化の下限
どんな最適(一情報源記号あたりの平均符号長を最短にした)化を行ったとしても、その結果得られる符号の長さは
を満たす。式の導出:
以下の最適化問題を定義。
この時、
となるようなを求めるとであり、このとき制約条件が有効制約となるためにはである。よってと求められる。ここからもっとも短い場合でとなることが分かる。
演習問題5.04
a
略。もっとも確率の低い葉を二つ選んでまとめる。そのまとめたものを「二つの葉の確率の和」をそのまとめたものの出現確率として一つの葉にする。以上の繰り返し。木の構造は一通りだけど、0,1の付け方は二通りある。
b
略。3 + 2n 個の葉をもつ木だからダミーの要素を加える必要もない。
演習問題5.05
一つ目の分布のシンボルをハフマン符号化するとその平均符号長は。
ハフマン符号(ハフマンふごう、Huffman coding)とは、1952年にデビット・ハフマン(英語版)によって開発された符号である。コンパクト符号やエントロピー符号の一つ。*16
コンパクト符号(コンパクトふごう)とは、一意に復号可能な符号のうち、同じ符号アルファベットを用いる他の任意の符号よりも、平均符号長が大きくない符号のこと。*17
二つ目の符号をハフマン符号化して平均符号長をもとめると。ハフマン符号はコンパクト符号だからこの符号長を下回る平均符号長をもつ符号は無い。
演習問題5.06
a
○。三要素でハフマン符号化したら同じになる。
b
×。符号長1の葉が既に無い。
c
×。符号長1の葉が既に無い。
演習問題5.09
符号長は常に自然数をとるのに、エントロピーは連続な関数だから自然数の値をとるとは限らない。だからエントロピー関数の値が自然数にならないような確率分布を与えればよいのだから例えば のような記号が含まれる符号を作る。
演習問題5.12
a
略。
b
すべて平均符号長が2になる。
c
すべての符号の確率についてを計算する、その値とハフマン符号化した結果の符号長をくらべるとのほうが小さい部分が出てくる。ことが分かる。(ただしハフマンはコンパクト符号だからこの符号長を下回る平均符号長をもつ符号は無い、だから平均したらハフマンのほうが短い。)※シャノン符号化
符号化の原理
圧縮したいデータに出現する記号の個数を求め、その個数で記号をソートする。
ソートしたデータを、なるべく総数が等しくなるようなところで二分割する。分割した片方のデータに0、もう片方のデータに1を割り当てる。
分割して出来た2つのデータをそれぞれ更に二分割していき、同様に0と1を割り当てていく。
*18
演習問題5.14
はじめに、確率変数のとりうる値が6種類しかないから符号アルファベットの種類が三種類のときにはそのままではうまくハフマン符号を作るための木が構成できない。だから一つダミー(出現確率0の葉)を加えればいい。
a
略。平均符号長。
b
ダミーを追加、平均符号長
c
符号アルファベットの種類が三種類の場合の方が平均符号長が少ないことが以上より分かる。
演習問題5.16
長いので後ほど追記するかも。
演習問題5.27
Sardinas–Patterson algorithm*19 などを参照。
演習問題5.28
a
であることは天井関数の定義から言える。ここからこの式をに関して総和をとって上記の式と問題の与えられた式は等しい。■
b
略。
第6章 ギャンブルとデータ圧縮
省略します。
第7章 通信路容量
通信路容量
通信路の入力に関する確率変数を,出力に関する確率変数を[tes:{Y}]と見る。
が通信路を通った結果のに重なりが無かったら常にを見たら入力のが分かる。
の値に関わらず出力の分布が同じならば
と式変形できる。
二元消失通信路*20
図はリンク先参照。の確率で入力が消失してしまうとき
<img src=\"https://cdn-ak.f.st-hatena.com/images/fotolife/m/misos/20201118/20201118144502.png\" alt=\"{
C \\
= max_{p(x)} I(X;Y) \\
= max_{p(x)} (H(Y) - H(Y|X") *1 \\
= max_{p(x)} (H(Y) - \sum_x p(x) H(Y|X = x)) \\
= max_{p(x)} H(Y) - H(\alpha)
}"/>
*1 \\
= max_{p(x)} (H(Y) - \sum_x p(x) H(Y|X = x)) \\
= max_{p(x)} H(Y) - H(\alpha)
}"/>特に、
について

だから

と考えられる。実際、

と書ける。以上から二元対称通信路の通信路容量は

対称通信路
二元対称通信路*21の一般化。通信路行列によって の条件付き分布が与えられているとすればその行列の第
の条件付き分布が与えられているとすればその行列の第 行は入力
行は入力 を条件付けしたときの
を条件付けしたときの の分布でありその行ベクトルを
の分布でありその行ベクトルを と記述する。
と記述する。

とできる。等号が成り立つのは出力が一様分布の時(そもそも、離散ならばエントロピーを最大にする分布は一様分布、連続ならばガウス分布)。そして出力を一様分布にするような入力の分布を求めればいい。対称通信路だからそれも同様に一様分布だと分かる。
演習問題7.01
a
今、が通信路をとおりとなってそれに対して変換 としたのだからこの一連の変換
としたのだからこの一連の変換 に対してデータ処理不等式
に対してデータ処理不等式

が言える。通信路容量の定義式に当てはめると

となるので、通信路容量は改善しない。
b
で等号がなり縦倍いのだから、 が1対1の変換であればいい。
が1対1の変換であればいい。
演習問題7.02
 であり
であり 、
、だから
 。なのでの要素の数によって場合分けする。
。なのでの要素の数によって場合分けする。

によって入力にノイズが加わることはないから、 。
。

によって入力にノイズが加わることでの要素が増える。
 を計算。
を計算。

によって入力にノイズが加わっても は入力でないと分かるから、。
は入力でないと分かるから、。

関連記事や参考文献及び引用文献元へのリンク
*3:http://www.neuro.sfc.keio.ac.jp/~masato/study/SVM/lagrange.htm
*9:引用元:参考文献 第三章、同一問題の問題文より
*13:Variable-length code - Wikipedia, the free encyclopedia
*19:Sardinas–Patterson algorithm - Wikipedia, the free encyclopedia
*22:Noisy-channel coding theorem - Wikipedia, the free encyclopedia
*23:Additive white Gaussian noise - Wikipedia, the free encyclopedia
*1:x_i,\dots,x_n) \in \chi^n) \geq 1 - \epsilon}"/>を満たす十分大きなnが存在する
証明: これらの性質から典型集合に属していない列の出現確率はnを十分大きくすればの要素数は 以下である
以下である
ひとつめは定義式の両辺のlogをとって漸近的等分割性を適用するとすぐわかる。
ふたつめは とすればいい。他の性質もはじめに書いた参考文献に記載されている。
とすればいい。他の性質もはじめに書いた参考文献に記載されている。 によって押さえることができる。つまり、符号の平均長を考えるときに典型集合に属していない符号の長さを(以下でしか出現しないから)無視できるようになる。その結果として一情報源符号あたりの符号の長さは
によって押さえることができる。つまり、符号の平均長を考えるときに典型集合に属していない符号の長さを(以下でしか出現しないから)無視できるようになる。その結果として一情報源符号あたりの符号の長さは 以下であるようにすることができると分かる。
以下であるようにすることができると分かる。
演習問題3.02
[tex:{
- \frac{1}{n} \log \frac{p(X^n) p(Y^n) }{p(X^n , Y^n)} \\
= -\frac{1}{n} \log \prod_{k=1}^n \frac{p(X_k) p(Y_k)}{p(X_k , Y_k)} \\
= -\sum \log \frac{1}{n} \frac{p(X_k) p(Y_k)}{p(X_k , Y_k)} \\
->_{n -> \infty} E(-\log \frac{p(X) p(Y)}{p(X, Y)})
}]
そして最後の式は相互情報量の定義の式そのもの。そして相互情報量は二変数が完全に独立のときに0になるのだから問題の与式は1に収束。
演習問題3.04
問題は
と記号を定義する。
a
漸近等分割性から言える。
b
各回の試行において各事象の起こる確率というものが、試行回数を重ねることで、各事象の出現回数によって捉えられるというのが大数の法則の主張するところ
やがて平均に収束することを踏まえると

である。ここからあ以下の条件を満たす十分小さな値 と自然数
と自然数 が存在する。
が存在する。


だからこれらをともに満たす集合に属する確率は

よって正しい。
c
出現する要素の確率をすべて足したら1になることから

であり、典型集合に含まれる要素の確率は

なのだから、

d
典型集合に含まれる要素の確率は

であり、ある十分大きい実数Mで

となるMが存在することは問bより分かる。よって問cと同じような解き方で(M > M)として

と求められる。
演習問題3.06

であり、

を代入して、

となる。

 。
。
 が言える。この式の両辺を変形すると問題の式が導ける。
が言える。この式の両辺を変形すると問題の式が導ける。 の展開。)
の展開。)
 から離れるほど「当てにくい」ことから真っぽく見える。だけど問題に「
から離れるほど「当てにくい」ことから真っぽく見える。だけど問題に「 は
は )
)



 の大小関係が言えればいい。
の大小関係が言えればいい。 と言っていい。Zについても
と言っていい。Zについても 。このことから
。このことから

 になるので0.
になるので0.
 とする。以上から
とする。以上から
 。なぜなら
。なぜなら から
から だけ離れているから。
だけ離れているから。
 を引くと
を引くと







 を求めると
を求めると であり、このとき制約条件が有効制約となるためには
であり、このとき制約条件が有効制約となるためには である。よって
である。よって と求められる。ここからもっとも短い場合で
と求められる。ここからもっとも短い場合で となることが分かる。
となることが分かる。 。
。 のような記号が含まれる符号を作る。
のような記号が含まれる符号を作る。 を計算する、その値とハフマン符号化した結果の符号長をくらべると
を計算する、その値とハフマン符号化した結果の符号長をくらべると のとりうる値が6種類しかないから符号アルファベットの種類が三種類のときにはそのままではうまくハフマン符号を作るための木が構成できない。だから一つダミー(出現確率0の葉)を加えればいい。
のとりうる値が6種類しかないから符号アルファベットの種類が三種類のときにはそのままではうまくハフマン符号を作るための木が構成できない。だから一つダミー(出現確率0の葉)を加えればいい。 。
。
 であることは天井関数の定義から言える。ここから
であることは天井関数の定義から言える。ここから



 の確率で入力が消失してしまうとき
の確率で入力が消失してしまうとき