正規分布に関する標本平均と標本分散
- 地域で特に重い上位a%はどれくらいの体重がある?
- n人適当に選んでその平均がb以上の体重をもつ確率は?
- n人適当に選んでその標本分散がc以上の体重をもつ確率は?
- 二人適当に選んでその体重差がd以上になる確率は?
- 適当に一人えらんで体重を記録していく、100人記録したときに総重量が5500を越える確率は?
1.
標準化した確率変数
 は
は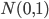 分布に従う。よって正規分布表において
分布に従う。よって正規分布表において
 の変数変換を行う。この時のYの
の変数変換を行う。この時のYの を代入すると標準
を代入すると標準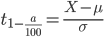 となるようなXが解。
となるようなXが解。2.
n人適当に選んだときの標本平均をもとめる式はであり、その分布を求めることで確率を求める。
![{ E(\bar{\mu}) \\
= E[ \frac{1}{n} \sum_{k=1}^n x_i ] \\
= \frac{1}{n} \sum_{k=1}^n E[x_i] \\
= \frac{1}{n} n \mu \\
= \mu
}](https://cdn-ak.f.st-hatena.com/images/fotolife/m/misos/20201118/20201118152334.png)
だから標本平均の分布の平均は母平均に一致する。標本平均の分布の分散は
だから標本平均の分布は
 。
。
このことから「n人適当に選んでその平均がb以上の体重をもつ確率」を求めるためにはn人選んだときの標本平均の分布 と標準正規分布表を結びつける必要がある。だから標準化をした確率変数
と標準正規分布表を結びつける必要がある。だから標準化をした確率変数 から解が求められる。
から解が求められる。
3.
標本分散の分布は正規分布に関連付けてとくことはできない。
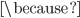 分散は二乗和の平均値であって、確率変数の二乗がでてくるから単純に「独立な確率変数の和の平均はそれぞれの分布の平均の和」であることを用いて分布の平均を求めることはもうできない。
分散は二乗和の平均値であって、確率変数の二乗がでてくるから単純に「独立な確率変数の和の平均はそれぞれの分布の平均の和」であることを用いて分布の平均を求めることはもうできない。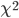 分布を用いるべきだときづく。
分布を用いるべきだときづく。
独立に標準正規分布に従う k 個の確率変数 X1, ..., Xk をとる。 このとき、統計量
の従う分布のことを自由度 k のカイ二乗分布と呼ぶ。

独立な標準正規分布をもつ確率変数をつくるためには とすればいいからこの形の変数の二乗和ならばこの分布に結びつけられる。分散Yを求める式は
とすればいいからこの形の変数の二乗和ならばこの分布に結びつけられる。分散Yを求める式は なのだから両辺を母分散
なのだから両辺を母分散 で割ってnをかけた
で割ってnをかけた

は分布(自由度n-1)に従う。すなわち の分布が分かるのだから解が求まる。
の分布が分かるのだから解が求まる。
4.
標本の差の分布を求める必要がある。それぞれ独立にとるとして新しい確率変数 の分布が分かればいい。もしもYの母平均と母分散が既知ならば標準化して
の分布が分かればいい。もしもYの母平均と母分散が既知ならば標準化して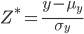 とすればいいことに気づくからこの分布を求めるためにつくる必要がある標準化した確率変数は
とすればいいことに気づくからこの分布を求めるためにつくる必要がある標準化した確率変数は

に従うことから解が求められる。独立出ない場合はの分散は に従うことを利用する。そもそも二つの確率変数の定数倍の和と差の分散は
に従うことを利用する。そもそも二つの確率変数の定数倍の和と差の分散は

から求められる。今は独立なので共分散はゼロで、a = 1,b = -1とした。
5.
100人選んだときの総和の分布を求めればよい。「独立で統一の分布に従う標本」「復元抽出」であると仮定することを明記したうえで100人の総体重の分布は に従う、あとは標準化して正規分布表と照らし合わせる。
に従う、あとは標準化して正規分布表と照らし合わせる。