かっぱ橋に行ってみた
また今度行って買うとき用のメモです。
ナカオファクトリーワークス



とうしょう釜





ユニオンコーヒー


小松屋


ヤマヤ商店



The Art of Tea TOKYO


中尾


KOSAI



釜浅商店



バイスー


ウェブとワードで動作する公用文の校正ツールを作った
主な機能
- 常用外漢字のチェック
- 数字表記の正しさや漢数字の使い方
- 重言・二重表現のチェック
- ですます調の言葉
- 句読点・符号・特殊記号など
「新しい『公用文作成の要領』に向けて(報告)」(令和3年 文化審議会国語分科会)、「公用文作成の要領」(昭和27年 内閣官房長官依命通知別紙)に記載されているルールはほとんどすべて網羅しているつもりです。

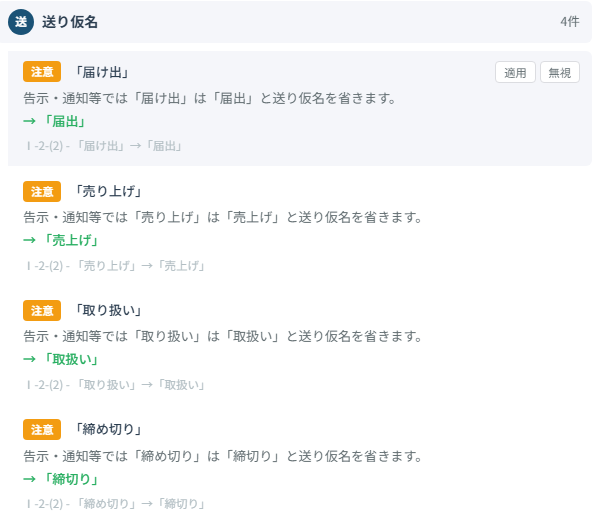
オンマウスで注意されている理由が表示され、その場で修正もできます。1000文字までは無料で使用できます。ぜひ使ってみてください。
ウェブサイトを刷新した
もろもろのウェブサイトの見た目やデザインをGPTの助けを借りて刷新しました。
- ジオゲッサー
- トップページ
- ジオゲッサーでフランスを見分ける
- 多言語にも対応(インドネシア語ページ・英語ページ)
- K_DM
- PLS 回帰について
- 決定木のパラメータについて
- pythonによる可視化実装例
- こちらも多言語対応(英語トップページ・スペイン語トップページ)
- レシピサイト
幸いどこも一定のアクセスがあるページなので、今後も時間があれば更新していきたいと思います。
Androidで2Gをオフにする手順
概要
偽の基地局を使ってスマホを2Gに切り替え、脆弱なセキュリティをついてSMSなどを傍受されるという案件が散見される。その対策として勝手に2Gに接続しないようにしたい。
手順
設定→ネットワークとインターネット→SIM→使用しているSIM選択→2Gを許可をoff



大学の研究室を訪問してみた
今、自分が仕事にしていることの他にあたらしいことができないかと思い大学院の研究室の先生と会ってみました。 (実は去年にも行ってました)
自分が大学院を出る時も博士に行かないか、という話は一応あったのですが、正直あのころはお金も無かったし自分の家系で一番働けるのが自分だったのでこのまま勉強ばかりしていいのかという不安もあったと記憶してます。
ちなみに、訪問した研究室の内容は介護についてです(←自分の専門とは関係無いです)。
地元にいたころから自分が大学を出るくらいまで祖母を介護していたのですが、正直自分の中ではその時間は人生の中で大変だった時期でした。そのあと周りの人のおかげや運に恵まれたこともあり、大学もなんとか卒業して仕事もなんとかこなせてます。 でも、なんだか自分はこれまでお世話になった人にお礼のようなものができていない気がして、 今になってそんな人達に役に立てる技術をつくりたいなという気持ちが生まれた感じです。
結論から言うと、なにかしら研究や技術開発はできるんだろうなと感じます。でも、今すぐには大学に通って何かすることはできないと思いました。
仕事やプライベートのことも考えないといけないし、たぶん周りの人に迷惑をかけることも増えることを考えると結構複雑な思いです。そしてそもそも今している仕事も好きなので、わざわざそれを削ってまですることなのか?という問いもありました。また、自分の仕事の立場や忙しさを考えると研究と仕事の両立はかなり難しいです(一方で世の中には『それでもやるぞ!』という強い意思で研究をしている人も大勢いて本当にすごいと思います)。
あと欲張りすぎるかもしれないですが、自分の専門性を深めるような研究室で博士を取るというルートもあります。それとの天秤もまだ決め切れていません。
こんな『なんとなく』な感じで受け入れて相談にのってくれた研究室の方には感謝してます。思い切ってメールしてみてよかったです。自分の中でももうすこし将来何をしたいかとか整理するきっかけになりました。
youtubeのショートに投稿するためのPremiere Proの設定
画像のサイズが正しいのにshort判定されないケースがいくつかあったため、うまく動作したケースをメモしておく。
ひとことでいうと、形式=H.264・プリセット=ソースの一致の場合はショート判定される。Youtube 1080p フルHDはショート判定されないことがあったので使用しない。
以下、short判定された動画の出力設定。 出力サイズは横幅1080pxx縦幅1920pxとしている。
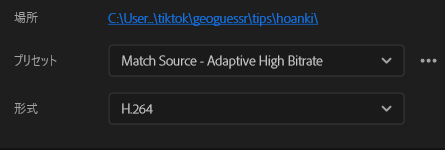
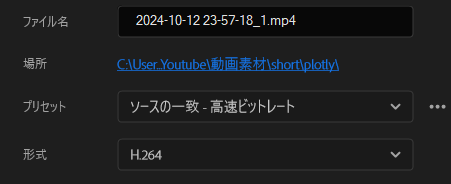
実際に投稿したものは以下↓、ショートフィードの一部として表示されていることが分かると思います。