情報理論のメモ
あくまでメモなので、"定義域を○×として、..."といった記述はないです。
参考文献
- ELEMENTS OF INFORMATION THEORY : Thomas M.Cover, Joy A.Thomas
- 情報理論 基礎と広がり: Thomas M.Cover, Joy A.Thomas, 山本 博資, 古賀 弘樹, 有村 光晴 他

漸近等分割性
AEP(漸近等分割性)の定義
が成り立つ、そしてこの性質をAEP(漸近等分割性)と言う。
※参考文献p43より参照。
証明:i.i.d.つまり独立で同一の分布に従う確率変数の列の同時分布は  で記述されるので、
で記述されるので、
と式を書き換えることができる。さらに

であることを考慮すると、
■
典型的集合の定義
ここで、すべての長さnの確率変数列の内でとくに”よく出る”nの長さをもつ文字列の集合Tは以下の性質をもつだろうと考える...
- もしも
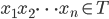 ならば
ならば  はほぼみんな同じくらい。
はほぼみんな同じくらい。 - 長さnの文字列のうちとなる率は1に近い
- Tの要素数は上限あり(ないと全要素いれればいいことになってしまう)
そしてここで典型的集合を定義する。英語版p59参照。
典型的集合(typical set)
 であるなら
であるなら

となるような集合を典型的集合と定義。
こうすることで、
- もしもならば はほぼみんな同じくらい。
これは定義が としているのだからみんな
としているのだからみんな に近い確率を持つ。
に近い確率を持つ。
- 長さnの文字列のうちとなる率は1に近い
この式と漸近等分割性の式を比べると成り立つことが分かる。
- Tの要素数は上限あり(ないと全要素いれればいいことになってしまう)
さらにすべての確率を足したら1になるはずなので

が(明らかに、あまり使うべきではない言葉だけど...!)わかる。よって

である。そして
- 十分大きな自然数Nについて、

も同様の式変形で導かれる。
確率変数列を符号化したときの平均符号長
以下、 と記述する。これらを0,1のみを使って符号化するときにどれくらいの長さのコードが必要かを調べるために、情報源から出現しうる
と記述する。これらを0,1のみを使って符号化するときにどれくらいの長さのコードが必要かを調べるために、情報源から出現しうる のパターン
のパターン を典型的集合である
を典型的集合である とそうでない
とそうでない に分けて符号化することを考える。
に分けて符号化することを考える。
まず、典型的集合の要素数には上界と下界があって、もっとも符号が長くなり売るのは要素数が最大の時で の数の要素がある場合が最大である。今は二ビットコードで符号化することにしているから、典型的集合を要素の重複無く符号化するには最低で
の数の要素がある場合が最大である。今は二ビットコードで符号化することにしているから、典型的集合を要素の重複無く符号化するには最低で の長さの符号があればいい。1ビット分は
の長さの符号があればいい。1ビット分は が整数で無い場合も成り立つことを保証するために必要。
が整数で無い場合も成り立つことを保証するために必要。
さらに、典型的集合に含まれる列かどうかを示すフラグを立てるビットをもう一つつけて ビットが典型的集合に含まれる列の符号化に必要なビット数とする。このとき、長さnのすべてのパターンを符号化するときの平均符号長は...
ビットが典型的集合に含まれる列の符号化に必要なビット数とする。このとき、長さnのすべてのパターンを符号化するときの平均符号長は...
■
と求められる。上の式の両辺をnで割って極限をとれば、一情報源符号あたりの平均符号帳がその情報源のエントロピーに近づくことが確認できる。
 がある時に
がある時に


