情報源及び出典、参照元
- Stanford engineering everywhere artificial intelligence | machine learning
- Stanford School of Engineering - Stanford Engineering Everywhere
- 講師:Andrew Ng (敬称略) 、著作権表示及び授業関連資料は上記サイトを参照してください。
- この記事の中の図の引用元
- Stanford School of Engineering - Stanford Engineering Everywhere
- それぞれの引用した図で、引用元(上記ページのpdfファイル名)を明記します。
- Stanford engineering ever に関するFAQ
- http://see.stanford.edu/see/faq.aspxを参照して下さい。
- 元サイトの著作権表示 Attribution 3.0 United States (CC BY 3.0 US) の日本語訳はここにありますが、誤解が無いように必ず英語ページを見てください。そして、この記事も同様にCC BY 3.0 USに従います。
※上記のページおよびpdf、上記以外の参考文献や関連ページを注釈の形でページ末尾に改めて記載します。
関連する文献
 |
 |
 |
黄色いのがいいです。
第六回授業メモ
Event models for text classication*1*2

ナイーブベイズを用いたテキスト分類 - 人工知能に関する断創録
上記すばらしい記事を参考にしたほうがわかりやすいのでこの項目については省略します。
Nonlinear classifiers(非線形分類器)

ニューラルネットワーク*4
が参考になるかもしれない。
- 微分可能な連続関数を出力するパラメータを決定づけるのに利用する
- 微分可能だからこそ次の「誤差伝播」が可能でそれによって「線形分離できない」問題もとけるようになる
- 誤差逆伝播法(バックプロパゲーション)*5など、データの進行方向は一方向ではない
- 二乗誤差をコスト関数とする

講義中のニューラルネットの概念図の記号に則って、
- 入力されるデータの特徴は

- 各ユニット(図の○)はそれぞれ別のパラメータ
 を持つ
を持つ - 関数
 はシグモイド関数(あえて言えば、連続で微分可能な関数)とする
はシグモイド関数(あえて言えば、連続で微分可能な関数)とする - 第k層のユニットは第(k-1)層のユニットの出力
 を要素にもつベクトル
を要素にもつベクトル を入力として
を入力として を出力とする
を出力とする
machine learning - What does the hidden layer in a neural network compute? - Cross Validated
Support Vector Machines(サポートベクターマシン*6 *7 )*8
- はじめに
 を計算
を計算
 の時、そしてその時に限り
の時、そしてその時に限り と予測
と予測 の時、そしてその時に限り
の時、そしてその時に限り と予測
と予測
- かつその値が大きいほど予測は”確からしい”
- かつその値が小さいほど予測は”確からしい”
マージンとは(直感的には)予測の確からしさの指標で、その値が大きいほどそのデータのクラス分類の予測は「確からしい」と言える。

もう一つの直感的な理解として上の図を見る。横切る直線(ただし直線に見えるのは二次元だからというだけで一般的な表現ではない)separating hyperplane*9:分割超平面とよばれるものでそこを境にクラスが分類される。マージンはこの超平面からの離れ具合と見て取れる。そしてサポートベクターマシンをモデル化するために以下の表記を導入する。

上記板書に従って以下では
 はパラメータ
はパラメータ とは分離した定数。
とは分離した定数。次に直感的だった「マージン」について定式化する必要がある。
Functional and geometric margins(関数マージンと幾何マージン)
machine learning - SVM - what is a functional margin? - Stack Overflow
より抜粋
"A geometric margin is simply the euclidean distance between a certain x (data point) to the hyperlane. "
I don't think that is a proper definition for the geometric margin, and I believe that is what is confusing you. The geometric margin is just a scaled version of the functional margin.
(そして偶然にもこの質問の解答で講義のNg氏の講義資料が登場していた..)
- 関数マージン(functional margin)
 の関数マージンを
の関数マージンを

と定義する。この式は の値がデータ
の値がデータ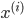 の正しい分類先であることに注意すると
の正しい分類先であることに注意すると  は「データの予測値を決める
は「データの予測値を決める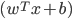 の符号とデータの正しい分類先の積」なのだからこの関数マージンが負の値になるのはデータの予測値の符号が正しい分類先の符号と異なる場合だけであることが分かる。よって関数マージンが正の大きい値であるほどその予測は確からしく、逆に負の値ならその予測は間違っていると判断できる。
の符号とデータの正しい分類先の積」なのだからこの関数マージンが負の値になるのはデータの予測値の符号が正しい分類先の符号と異なる場合だけであることが分かる。よって関数マージンが正の大きい値であるほどその予測は確からしく、逆に負の値ならその予測は間違っていると判断できる。
正規化項 はなぜ必要か。なぜならサポートベクターマシンの「マージン」は制限がなければいくらでも大きくできてしまうから。例えばもとの関数の結果を100倍するだけでもマージンは広がってしまうようにできる。だけどそれでは正確な分類ができるとは言えない。
はなぜ必要か。なぜならサポートベクターマシンの「マージン」は制限がなければいくらでも大きくできてしまうから。例えばもとの関数の結果を100倍するだけでもマージンは広がってしまうようにできる。だけどそれでは正確な分類ができるとは言えない。
こうしてすべてのデータについての関数マージンを求めたとして

と書くことにする。
- 幾何マージン(geometric margin)

上の図でいう各データ点と分割超平面(図の黒直線)との間の距離こそが幾何マージン。そしてこの距離をどのようにはかるかが問題、そこで分割超平面に重なって存在する任意の点 では
では であることを利用する。図をもとに考えるとこのときデータ点Aのもつ幾何マージンは「直線ABの長さ」でありつまり
であることを利用する。図をもとに考えるとこのときデータ点Aのもつ幾何マージンは「直線ABの長さ」でありつまり

でありもちろん

が成り立つ。これを記号で書き直すと

でありこの式から求めたい幾何マージン を求められる。すなわち
を求められる。すなわち

と求められた..!しかし注意すべきは の場合、関数マージンと幾何マージンの式は違いがないこと、そして幾何マージンは重みづけ
の場合、関数マージンと幾何マージンの式は違いがないこと、そして幾何マージンは重みづけ を定数倍しても変化しないこと。
を定数倍しても変化しないこと。
最適マージン分類器(optimal margin classifier)
それじゃあ「よいSVM(サポートベクターマシン)」って何?という話になる、つまり「よい」と判断する指標が必要。ここで言葉の意味を定義。
- サポートベクトル
- クラスを分割する超平面に対して最も小さい(幾何)マージンを持つ点
サポートベクターマシンは途中までやって次回(以下)の講義にまたぎます。
(OCW)機械学習の授業のめもその4 - 雑なメモ
参考文献と関連ページ
- Stanford engineering everywhere artificial intelligence | machine learning
- 記事の中の図の引用元
- Stanford engineering ever に関するFAQ
- 元サイトの著作権表示 Attribution 3.0 United States (CC BY 3.0 US)
- FrontPage - 機械学習の「朱鷺の杜Wiki」
- DM825 - Introduction to Machine Learning
- 上記のページおよびpdf以外の参考文献や関連ページ
*1:McCallum, A. and Nigam K. "A Comparison of Event Models for Naive Bayes Text Classification". In AAAI/ICML-98 Workshop on Learning for Text Categorization, pp. 41-48. Technical Report WS-98-05. AAAI Press. 1998,pdf
*2:cs229-notes2.pdf page12以降
*4:http://www-ailab.elcom.nitech.ac.jp/lecture/neuro/menu.html
*5:http://ipr20.cs.ehime-u.ac.jp/column/neural/chapter6.html
*7:関連資料;http://see.stanford.edu/materials/aimlcs229/cs229-notes3.pdf
*8:映像43:43~
*9:Supporting hyperplane - Wikipedia, the free encyclopedia
*10:引用元;https://www.youtube.com/watch?v=qyyJKd-zXRE#t=4063
*11:引用元:cs229-notes3.pdf